Home › AI Governance Insights › The Five Data Observability Metrics Every AI Governance Team Should Know
The Five Data Observability Metrics Every AI Governance Team Should Know
By F. Jay Hall, Founder, GRC Careers LLC · June 28, 2026 · 5 min read
Artificial intelligence is only as trustworthy as the data behind it. Organizations pour months into evaluating models, choosing LLMs, and writing governance policy, yet a large share of AI failures start long before a model ever returns an answer. They start with the data.
Data observability is how teams stay ahead of that. It gives continuous visibility into the health of your data pipelines, so problems surface early instead of showing up as a wrong number on an executive dashboard or a bad recommendation from an AI assistant.
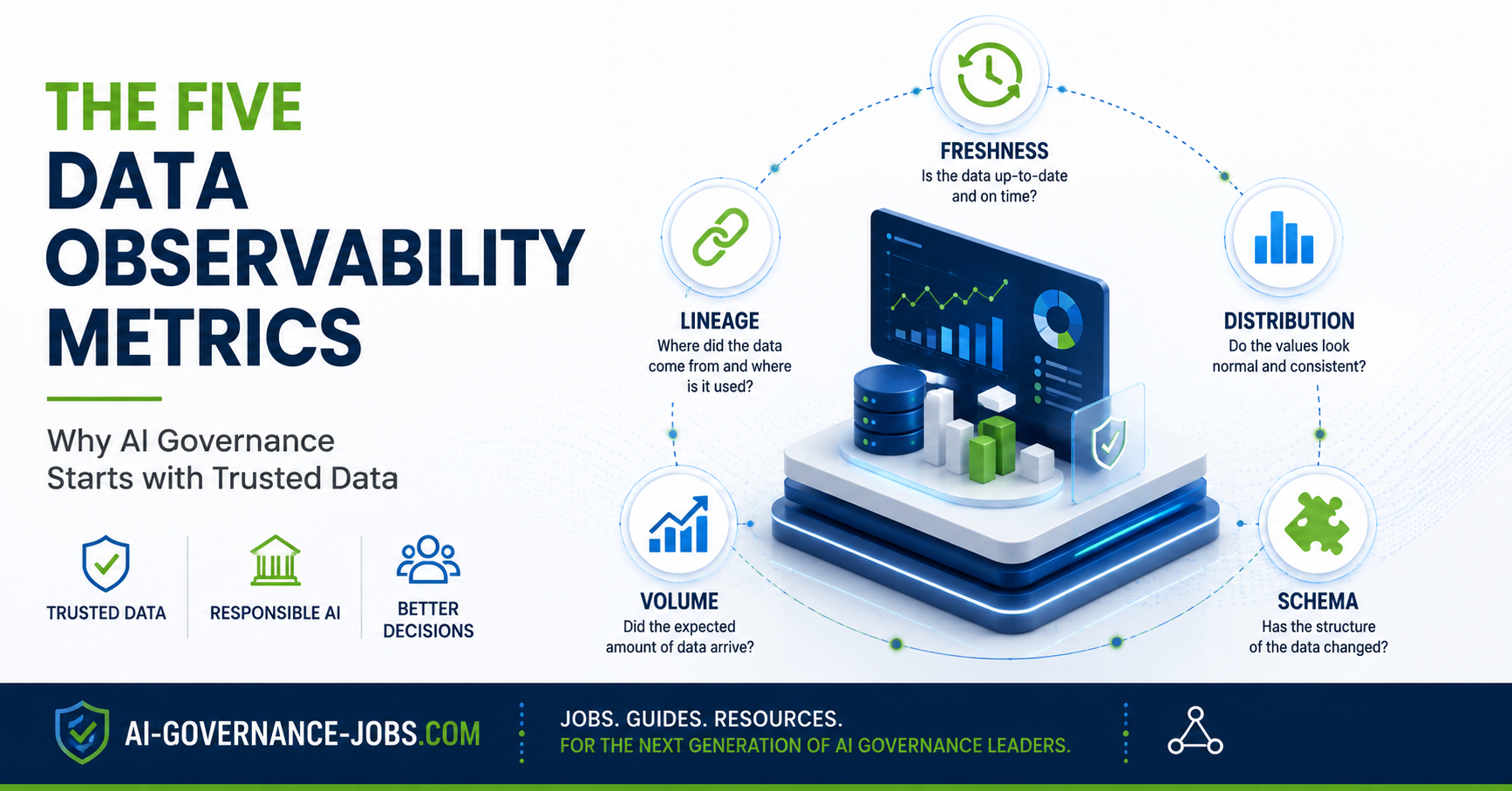
If your organization runs on Databricks or a similar modern data platform, five metrics make up the core of a working observability practice. Here is what each one watches, and why it matters to anyone responsible for governing AI.
Key Takeaways
- Data observability helps organizations catch data issues before they reach AI systems.
- The five core metrics are Freshness, Distribution, Schema, Volume, and Lineage.
- Strong observability improves trust, transparency, and AI governance.
- Data quality directly shapes AI reliability and the business decisions built on it.
- Observability complements both data governance and AI governance programs.
What Is Data Observability?
Data observability is continuous monitoring of the data moving through your pipelines: where it came from, whether it arrived, whether it looks right, and who depends on it downstream. Instead of learning about a data problem when a business user complains, you catch it at the source.
Why It Matters for AI Governance
Data governance sets the rules. AI governance assigns accountability. Observability is the visibility that makes both real. As organizations push generative AI, autonomous agents, and predictive models into daily operations, whether the underlying data can be trusted stops being an engineering detail and becomes a governance question. Reliable AI rests on trusted source data, consistent quality, transparent lineage, early anomaly detection, and continuous monitoring of production pipelines.
Freshness
Is your data arriving when it should? Many AI applications depend on regularly refreshed datasets. If yesterday's data never lands, a dashboard, a forecast, or an AI assistant keeps making decisions on stale information. Freshness monitoring alerts teams when a scheduled update fails, before the stale data spreads.
Distribution
Does today's data look like yesterday's? Not every problem involves missing records. Sometimes the structure holds but the values shift hard. A spike in nulls, unexpected demographics, or strange transaction patterns can signal data drift or an upstream bug. Watching statistical distributions catches these changes before they reach analytics or a model.
Schema
Has the structure of your data changed? Adding a column or changing a data type looks harmless. In practice it can break downstream reports, ETL jobs, and AI workflows with no warning. Schema monitoring flags structural changes so engineering can fix compatibility issues before they cascade.
Volume
Did the expected amount of data arrive? Sudden drops or spikes in record counts often mean an ingestion failure, duplicate processing, or an incomplete dataset. Volume monitoring is the early warning that something is missing or doubled, before business users act on a bad report.
Lineage
Where did this data come from? Lineage documents how data moves through the organization: source systems, transformations, dependencies, and downstream consumers. When an issue hits, lineage lets teams pinpoint which reports, models, or AI applications were affected.
AI Governance Insight
For Responsible AI programs, lineage does double duty. It supports transparency, auditability, and the evidence regulators ask for. When something breaks, lineage is how you trace every report, model, and application that touched the bad data.
The Bottom Line
Data governance establishes the rules. AI governance establishes accountability. Data observability is the visibility that makes both work. Organizations investing in AI should treat observability less as one more monitoring tool and more as the foundation under every AI system they expect to trust.
Image inspiration for this article drew on educational material from DQLabs on core data observability concepts for Databricks.
Related Guides
- The AI Governance Frameworks Every Hiring Manager Expects You to Know: NIST AI RMF, ISO 42001, and the EU AI Act, and how they fit.
- Data Governance: who owns the data and how it stays trustworthy.
- AI Governance careers: the field, the roles, and how to break in.
- Responsible AI: turning principles into day-to-day practice.
- AI Risk Management: spotting and managing model risk.
- How to Become an AI Governance Analyst: the step-by-step roadmap.
- AI GRC roles: open governance, risk, and compliance jobs.
Frequently Asked Questions
What is data observability?
Data observability is continuous visibility into the health of an organization's data pipelines: whether data arrived on time, whether its values and structure look right, how much arrived, and where it came from. It lets teams catch data problems at the source before they reach dashboards or AI systems.
What are the five data observability metrics?
Freshness, Distribution, Schema, Volume, and Lineage. Freshness tracks whether data arrives on schedule, Distribution watches whether values look normal, Schema detects structural changes, Volume checks that the expected amount arrived, and Lineage maps where data came from and what depends on it.
Why does data observability matter for AI governance?
AI is only as reliable as the data behind it. Data governance sets the rules and AI governance assigns accountability, but observability provides the visibility that makes both work, catching the data issues that cause AI failures before they affect decisions.
How does data lineage support Responsible AI?
Lineage documents how data moves through an organization, including sources, transformations, and downstream consumers. That supports transparency, auditability, and regulatory compliance, and it lets teams quickly identify which models or reports were affected when a data issue occurs.